|
Pipeline Architecture: Based on our analysis of execution time for both single end read and paired end reads , we merged the steps to build each stage of the pipeline.
Refer for details: PVT- Pipeline setup for processing multiple data files in Article
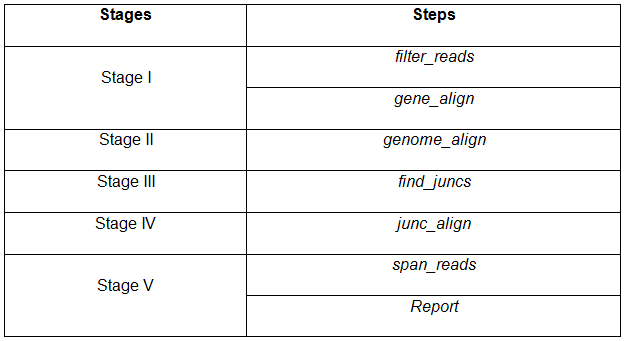 Figure: Spliced Alignment steps corresponding to each pipeline stage |
|
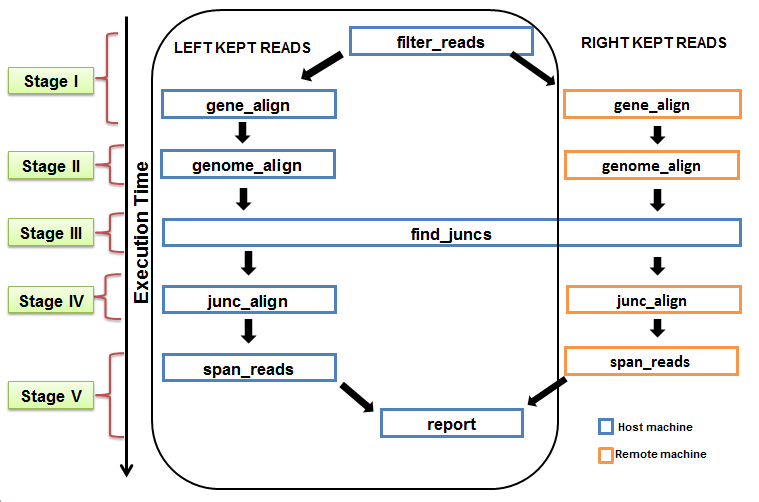 Figure: PVT pipeline showing the order of execution and different stages for single end and paired end reads. The step(s) comprising each stage is based on balanced length of pipeline stage. Single end read analysis pipeline is presented within black bordered box. |
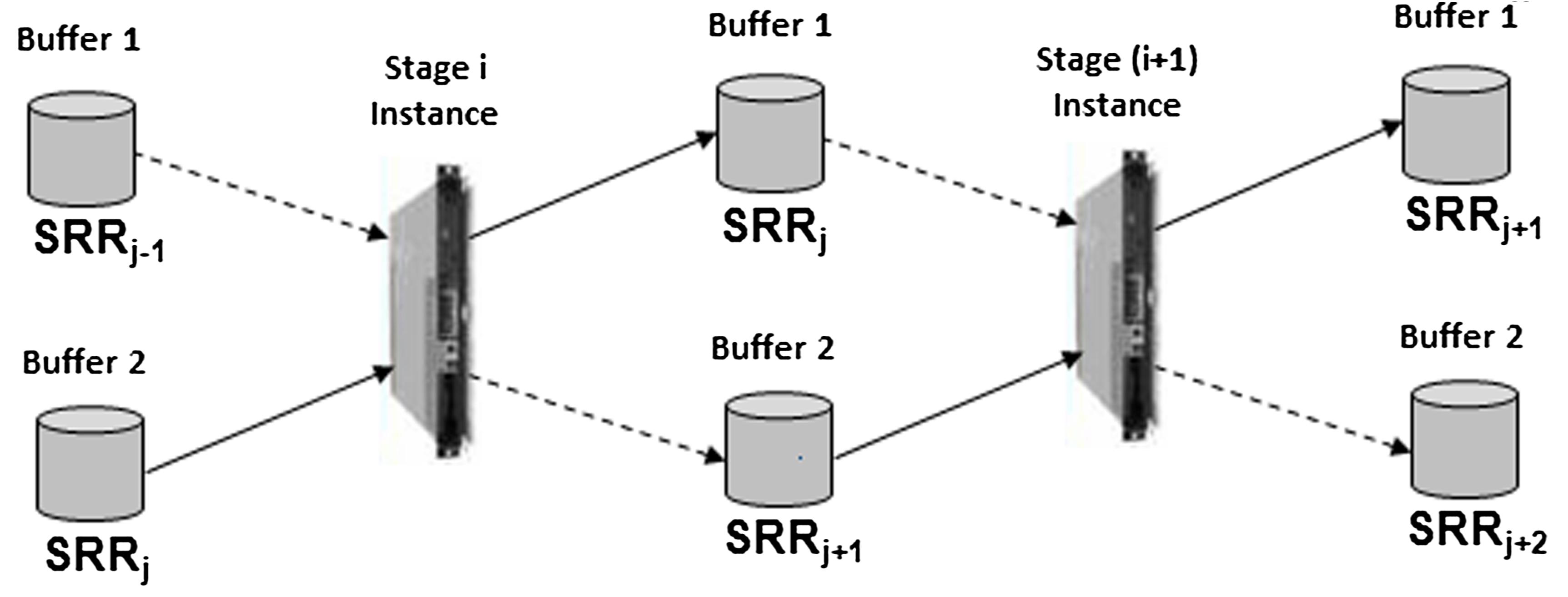
Cloud Set Up: PVT is able to overlap the execution of multiple data files and each pipeline stage works on a different execution step at the same time, it brings upon a huge improvement compared to TopHat. The PVT-Cloud set up can be implemented in a middleware based cloud architecture as shown below. Refer for more details: PVT-Cloud: pragmatic cloud architecture in Article |